

SAMPLE-BASED EFFECT GENERATOR
The RECODER is a new kind of musical tool that lets you turn any recorded phrase into a living, breathing unique audio effect:
Record any sound, a riff, a melody, a beat, a hiss, a glitch — and use the RECODER to imbue your dry signal with various properties of the captured “spectral donor”.
You can record from the main input, a separate REC input – or from the built in microphone!

You can think of it as a Cross-Pollinator, an Audio Prism, a Ghostly Vocoder, a Formant Shifter, a Granular Echo Creator, or a Sound Imprint Machine…
We’ve defined it as a SPECTRAL MORPHING WORKSTATION, but honestly – even we don’t fully know what the RECODER is yet, because it is specifically designed to produce a unique audio effect in every player’s hands.
READY TO ROLL THE DICE?
DETERMINISTIC SPECTRAL TRANSFER & CONVOLUTION ENGINE
The RECODER is a phrase-driven signal processor that converts any recorded audio input into an adaptive, parameter-dependent transformation system.
Any captured phrase — tonal, atonal, periodic, non-periodic, harmonic or noise-based — becomes a spectral donor, supplying multidimensional data: formant structure, transient topology, temporal contour, and frequency-distribution matrices.
These datasets are then used to modulate, convolve, resynthesize, imprint, or structurally transform the incoming dry signal.
Audio can be sourced from Input A (Main signal path), Input B (Dedicated REC bus), or from the unit’s internal microphone, each routed into the spectral acquisition stage for FFT-domain capture.
It can be interpreted as a spectral transfer matrix, a convolution-driven imprint engine, a dynamic formant translator, an adaptive granular decoder, or a phrase-based modulation processor.
We classify it as a Spectral Morphing Workstation, although its behavior is intentionally non-fixed and algorithmically dependent on user-input variation.
Its operational identity changes according to the spectral complexity, temporal structure, and excitation method used by each player.
READY TO INITIATE STOCHASTIC NON-DETERMINISTIC OUTCOME GENERATION BY METAPHORICALLY “ROLLING” ONE OR MORE RECTANGULAR SOLID OBJECTS — TYPICALLY UNIFORM SIX-FACED POLYHEDRA WITH EQUAL EDGE LENGTHS, COMMONLY REFERRED TO AS DICE — WHOSE TERMINAL RESTING ORIENTATION AFTER FREEFALL AND SURFACE COLLISION DETERMINES A DISCRETE NUMERICAL RESULT USED IN PROBABILITY-BASED DECISION SYSTEMS??
At its core, the RECODER is designed for single-input recording and processing. Plug your instrument into the Main Input — guitar, synth, voice, drum machine, acoustic pickup, modular — and just roll the dice:
1. Record a phrase by holding down the REC footswitch – the maximum length is 12 seconds;
2. See it being captured on the circular LED display;
3. As soon as you release the REC Footswitch – the phrase will start looping inside the memory buffer; after release;
4. Play your instrument through the phrase — and watch your live signal get interpreted, reshaped, filtered, sliced, and harmonically re-mapped – or RECODED – through that phrase…
Every phrase you capture can be saved permanently inside the pedal, stored in one of 234 memory slots –
along with all its customized parameters, layers, mangles, and mutations.
Short phrases (50–200 ms) behave like spectral filters, resonators, or timbral imprints;
Long phrases (up to 12sec) become living rhythmic maps, transient machines, vowel vocoders, spectral landscapes, phantom riffs that live inside your clean sound.
At its core, the RECODER is built for single-channel phrase acquisition and deterministic processing.
Connect any excitation source to the Main Input — guitar, synth, voice, drum machine, acoustic pickup, modular — and initiate phrase capture:
1. Hold the REC footswitch to begin buffer acquisition (maximum phrase length = 12 s).
2. Capture progress is visualized via the circular LED matrix (1 LED = 1 s).
3. Upon release of REC, the recorded phrase is written to volatile RAM and immediately enters loop-state.
4. Live input is streamed through that phrase as a reference dataset — where it is interpreted, filtered, time-sliced, convolved, resynthesized, and spectrally remapped using deterministic phrase-based convolution.
Each captured phrase can be permanently stored in non-volatile memory — assigned to one of 234 indexed slots — along with all mutation parameters, spectral transformations, layer states, and modulation configurations.
Micro-phrases (50–200 ms) function as spectral filters, resonant kernels, and timbral imprint matrices.
Macro-phrases (up to 12 s) behave as rhythmic convolution maps, transient arrays, formant distribution engines, spectral architectures, and deterministic phrase-based excitation systems.
The REC Input allows you to record external donor material from a different source in real time while still playing through your main instrument. That means you can create hybrid phrases from different sources without unplugging or stopping the flow, for example:
– Play guitar while grabbing phrases from your synth or groove-box;
– Record a vocal snippet while singing and use it to filter a drum loop, etc.;
But where the REC input truly shines, is the LIVE MODE – specifically designed to cross-pollinate instruments, pedals, synths & signals in real time.
This means that you’re no longer just playing through saved phrases — you’re feeding it new material mid-performance, constantly changing how the signals get RECODED.
The REC Input enables external donor acquisition from a secondary signal path in real time — while maintaining continuous excitation through the main input. This allows generation of hybrid phrase datasets without rerouting or interrupting signal flow. For example:
– Perform on the main input while capturing donor data from a synth or groove engine
– Capture a vocal imprint and use it as a spectral transfer matrix for a percussive source
Where the Record Input becomes structurally significant is in LIVE MODE — a dedicated real-time cross-modulation environment for continuous phrase replacement, donor injection, and inter-signal imprinting.
In this state, you are no longer processing through static, pre-saved phrase buffers —
you are actively feeding evolving donor material mid-performance, continuously redefining how the input signal is interpreted, filtered, convolved, resynthesized, and RECODED.

The White Layer is all about taking your dry signal and infusing it with the behavior, movement, and personality of the recorded phrase. There are four main controls:
AMPLITUDE – Transfer the Dynamics
Turn left → it subtracts the most active frequencies (a soft, pulsating tremolo that follows the phrase’s rhythm).
Turn right → it boosts those active bands, acting like a living multi-band booster — and if pushed far, it becomes a phrase-driven multi-band distortion.
TIMBRE – Transfer the Flavor
This control captures only the tonal DNA of the recorded phrase & superimposes it onto the input without changing dynamics.
It’s like borrowing the voice, texture, color, and grit of the phrase — and letting your playing speak through it.
Turn Left → vocoder-style imprint (grainy, glassy, responsive)
Turn Right → Additive resynthesis (cleaner, harmonic, melodic)
BANDWIDTH SWITCH – Coarse | Medium | Precision
This switch changes the WHITE LAYER’s BANDWIDTH:
how finely the amplitude & timbre engines process both signals:
LOW: Wide, chunky spectral bands; Thick, raw, lo-fi, expressive
MEDIUM: Partial spectral resolution, Balanced, musical, textured
HIGH: Full FFT spectral resolution (up to 1024 bands)
Super-detailed, surgical, spectral mapping.
Sometimes lower resolution sounds more musical.
Sometimes high resolution sounds more digital than digital.
Your call.
ATTACK & DECAY – Feel the Response Curve
These two knobs control how responsive, smooth, or sharp the transfer feels.
ATTACK: how quickly the Recoder reacts to your playing
DECAY: how long it “holds onto” the phrase’s energy before morphing to the next moment.
The White Layer applies deterministic parameter mapping between the dry input stream and the recorded phrase dataset using dynamic, spectral, and temporal transfer algorithms. It consists of four primary control domains:
AMPLITUDE — Multiband Dynamic Transfer Function
Executes dynamic convolution between the input’s amplitude envelope and the phrase’s energy-distribution coefficients.
• Turn Left → Attenuates spectral regions with highest activity in the phrase dataset, producing phrase-synchronous amplitude subtraction and rhythmic energy suppression.
• Turn Right → Increases gain in spectral regions indexed by the phrase’s transient-energy vector. At higher magnitudes, transitions into phrase-driven multiband distortion via non-linear transfer shaping.
TIMBRE — Spectral Fingerprint Transfer Algorithm
Performs convolution-based harmonic and formant embedding, applying the phrase’s spectral centroid, formant matrix, and partial-distribution topology onto the input, independent of amplitude.
• Turn Left → Low-order coefficient blending; vocoder-style transfer; coarse formant imprint; timbral color grafting; high textural density.
• Turn Right → Additive resynthesis; higher-order harmonic reconstruction; spectral smoothing; cleaner, harmonic-accurate imprinting.
BANDWIDTH SWITCH — Resolution Scaling (Coarse | Medium | Precision)
Controls FFT partition density and bin-resolution granularity for amplitude and timbre transfer:
• Low Resolution → 16–64 spectral clusters; broadband grouping; macro-imprint behavior; coarse, expressive, low-fidelity spectral emphasis.
• Medium Resolution → 128–256 partitions; partial spectral fidelity; balanced timbral accuracy and expressiveness.
• High Resolution → 512–1024 bins; full-spectrum precision; surgical mapping; analytically accurate transfer.
Lower resolutions emphasize macro-behavior and tonal character.
Higher resolutions emphasize spectral precision and analytical detail.
ATTACK & DECAY — Temporal Response Curve Shaping
Defines system responsiveness in the time domain for dynamic and spectral adaptation.
• Attack — Rise-time constant; determines how rapidly the live input aligns with the phrase-derived transfer function.
• Decay — Fall-time constant; determines persistence of the applied imprint before transitioning to subsequent transfer frames.
Together, these parameters shape responsiveness, temporal smoothing, and persistence of the spectral and dynamic imprint systems.


The Yellow Layer allows parts of the actual recorded material to start leaking into your output as an additional moving layer of sound.
SLICES – Blending in little pieces of the recorded phrase
Turn Right → adds overlapping, sympathetic spectral content from the recorded Phrase – harmonically aligned with what you are currently playing – Melodic, vowel-like, responsive.
Knob position determines the amount of signal added.
Turn Left → slices become unpredictable, dissonant, metallic, glitchy, broken, alien — based on the differences between your playing and the phrase.
RESONANCE – Real-time harmonic blooms from the recorded phrase.
Resonance analyzes the pitch and harmonic content of your recorded phrase and creates artificial boosted resonances on top of your dry signal.
Turn Left → the resonances follow what you’re currently playing, but shaped by the phrase’s tonal DNA.
Turn Right → the resonances are locked inside the phrase, regardless of what note you’re playing – creating strange harmonic overlays that sometimes agree, sometimes fight you — sometimes sound like your instrument is being haunted.
REPEATS & DISTANCE – Time-based mutation of those slices and resonances.
Once Slices and Resonances are triggered, these two knobs decide how they behave in time:
REPEATS: How many times those fragments are repeated — from one single blink to long, blooming, feedbacking tails. Invert the Knob to activate the Sound on Sound mode – thus stacking the delays.
DISTANCE: How widely spaced or tightly clustered those fragments are:
Turn Left → millisecond range where you can make granular washes that sound like a spectral freeze or a grainy reverb;
Turn Right → normal range that goes all the way up to 10 seconds – this is the ultimate playground for evolving textures.
The Yellow Layer introduces phrase-originating time-domain and frequency-domain events into the output signal path as an additional deterministic layer.
SLICES — Threshold-Based Granular Phrase Extraction
Generates phrase fragments by extracting micro time-windows when correlation between input excitation and phrase spectral data exceeds (or fails to exceed) defined band-specific thresholds.
• Turn Left → Fragment triggering prioritizes low-correlation events; selection biases toward high deviation between input and phrase spectral data (non-aligned, dissonant, non-predictive behavior).
• Turn Right → Fragment triggering favors high-correlation detection; phrase segments are extracted and aligned according to spectral similarity, harmonic matching, and temporal relevance.
RESONANCE — Convolution-Based Harmonic Reinforcement
Generates synthetic resonance structures by convolving the input spectrum with the harmonic and formant distribution coefficients derived from the recorded phrase.
• Turn Left → Convolution coefficients are modulated in real time according to input pitch and spectral position, constrained by the phrase’s frequency-distribution matrix.
• Turn Right → Convolution coefficients remain phrase-fixed, independent of input pitch; output presents static resonance mapping derived solely from phrase spectral architecture.
REPEATS & DISTANCE — Temporal Recurrence and Dispersion Control
Once Slices or Resonance events are triggered, these parameters govern recursion and temporal spacing.
REPEATS — Regulates event recurrence count and feedback persistence, from single-trigger operation to extended recursive propagation. Inverted knob mode enables cumulative sound-on-sound stacking.
DISTANCE — Sets temporal spacing between repeated events.
• Turn Left → Sub-100 ms range for granular clustering and continuous spectral-density accumulation.
• Turn Right → Extended spacing (up to 10 seconds) for macro-scale time dispersion and evolving transfer structures.

Since the RECODER is a pedal that sounds completely differently depending on what you feed into it – we’ve created a whole layer of controls dedicated to altering the recorded phrase itself:
TONE – Tilt the Energy:
This is a dramatically strong tilt-EQ engine that autonomously picks its center “tilt” point based on analysis of the recorded phrase or sample — so yes, even the TONE knob is alive & completely dependent on what you record:
DAMAGE – Obliterate the sample:
and start a chain reaction that changes everything you had dialled in…
Turn Left → bit reduction, digital degradation, crunchy broken beauty.
Turn Right → full-on wavefolding – shredding the phrase into aggressive, harmonic-dense chaos.
PITCH – eight whole octaves:
Turn the Pitch knob to drop or lift the entire recorded phrase by up to 4 octaves – but here’s the twist: the timing doesn’t change.
You get time-corrected pitch shifting – meaning you can record a tiny pinch harmonic and drop it down all the way to a rumbling thunder — without stretching or slowing it down.
STRETCH – Bend time without breaking the seams:
This is a time-stretching engine that is completely decoupled from pitch — take a 50-millisecond sample and stretch it into a grainy, long texture and enjoy the trip. Or, alternatively, you can record the intro to thunderstruck and speed it up so it sounds like a swarm of bumblebees.
RED Layer modifies the recorded phrase dataset itself, altering its spectral, temporal, and harmonic properties before any further transfer or convolution.
TONE — Autonomous Spectral Tilt Engine
Applies adaptive tilt equalization by shifting energy distribution around a dynamically computed spectral pivot point.
The pivot frequency is not fixed — it is derived from statistical analysis of the phrase’s spectral centroid, energy-weighted formant distribution, and dominant harmonic clusters.
All tilt behavior is phrase-dependent; no static EQ curves are used.
DAMAGE — Sample Degradation and Harmonic Mutation
Applies progressively non-linear transformation to the recorded phrase, altering its spectral and structural integrity.
• Turn Left → Initiates bit-depth reduction, quantization error, and digital aliasing artifacts. Harmonic and temporal resolution are reduced according to statistical truncation parameters.
• Turn Right → Engages wavefolding and harmonic multiplication, introducing non-linear distortion, spectral inversion, and high-density harmonic proliferation.
Modifying DAMAGE propagates through all dependent transfer engines (Amplitude, Timbre, Resonance, Slices, Pitch, Stretch).
PITCH — Time-Invariant Transposition Engine
Transposes the entire recorded phrase across an eight-octave span (±4 octaves) while preserving original temporal structure.
Time-independent pitch shifting maintains phrase duration, temporal segmentation, transient position, and rhythmic architecture without stretching or compression.
Applies phase-coherent resynthesis to preserve structural continuity.
STRETCH — Pitch-Decoupled Time Expansion and Compression
Performs time scaling on the recorded phrase while maintaining original pitch, spectral distribution, and formant structure.
• Expand short segments into extended granular structures, generating long-form spectral density without altering pitch.
• Compress long segments into accelerated micro-structures without pitch shift, maintaining spectral identity.
Time scaling is executed via pitch-decoupled granular resynthesis with phase-locking for coherence.


LOOP Mode: Circular Playback
This is the default mode – the one we’ve focused on in all previous sections, and the mode that inspired the RECODER idea initially!
In LOOP mode, the recorded phrase is constantly spinning inside the engine — like a circular buffer. The playhead continuously cycles through the phrase, over and over again.
STEP Mode: Dynamic Playhead
RECODER analyzes the recorded phrase and splits it into segments based on transients and pitch changes — like tiny “phrase markers” or event points.
The playhead only advances when you trigger it with your playing.
Each time you strike a note or hit a transient — the engine jumps to the next slice, segment, or pitch zone in the recorded phrase.
This is the ideal mode for breaking out of a set rhythmical pattern, and for introducing a sense of responsivity – where all changes in the RECODER’s spectrum come directly from you!
* Advance Sensitivity & Threshold can be adjusted in Global Settings.
LIVE Mode: Real-time side-CODING
Instead of relying on saved phrases as the signal source — the RECODER uses your live input as the spectral donor – essentially becoming a real-time spectral resynthesis and cross-morphing machine.
You can still record a phrase and RECODE through it – but as soon as you unlatch the REC Footswitch – you can go right back to the LIVE input as the modulation source.
LOOP Mode — Continuous Buffer Cycling
Default operational mode.
The recorded phrase is stored as a circular buffer. A fixed-position playhead continuously cycles through the entire phrase in a closed loop, maintaining uninterrupted time progression.
All spectral, temporal, and harmonic transfer computations are driven by the current playhead position within the phrase.
STEP Mode — Event-Driven Playhead Advancement
The recorded phrase is segmented into discrete units based on detected transient peaks, spectral discontinuities, and pitch-zone boundaries. These become internal event markers.
The playhead does not advance continuously — it advances only when triggered by the input signal.
When a new transient or note onset is detected at the input, the playhead jumps to the next indexed event marker (segment, slice, or pitch zone).
This yields phrase navigation that is directly mapped to user excitation.
Sensitivity, detection threshold, and segmentation density are adjustable in Global Settings.
LIVE Mode — Real-Time Side-Coding and Cross-Morph Resynthesis
In this mode, the spectral donor is no longer strictly the stored phrase. Instead, the engine dynamically acquires spectral frames from the live input and uses them for real-time convolution, harmonic transfer, and parameter resynthesis.
A stored phrase may still be used as a reference, but once the REC footswitch is unlatched, the system begins replacing donor frames continuously with incoming spectral data.
This enables live, continuously updated cross-morph processing — effectively converting the system into a real-time spectral resynthesis engine.
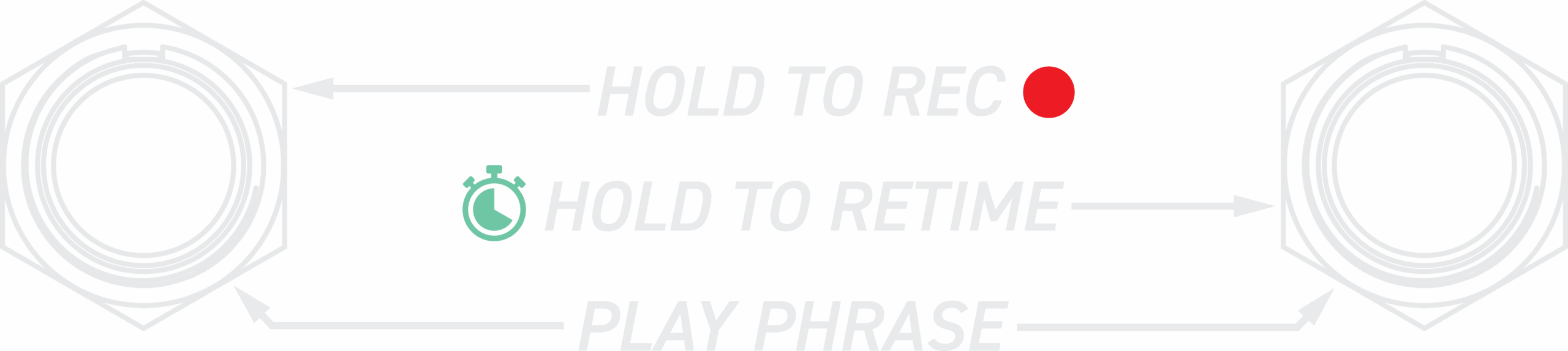
RECORD
Press and hold the REC footswitch to start recording. Recording starts as long as the switch is held down and stops when you release it.
Maximum phrase recording time is 12 seconds, but the recorded phrase can be as short as you like — even less than a hundred milliseconds.
Short captures behave like static filters, timbre captures, resonators, glitch artifacts. Long captures become looping “landscapes,” rhythmic machines, spectral vocoders, ghost riffs, etc.
PLAY PHRASE
Press both footswitches at the same time | REC + ENGAGE | and the RECODER will play the phrase directly through the output — with all of the RED parameters applied:
pitch, stretch, tone, damage.
This is extremely useful for:
– Checking what you actually recorded;
– Hearing how the Red Layer settings changed the phrase;
– Using the RECODER like a tiny sample playback or drone/phrase looper!
It’s not a looper pedal —
but yes, you can loop.
PHRASE RETIME
This is a clever shortcut for quickly re-timing or “stretch-aligning” the recorded phrase to match what you are playing now without changing pitch, stretch values, or any of the spectral content.
Let’s say you recorded a rhythmic pattern and you’re using it as a modulation source — but now you want to switch to a different tempo:
PRESS & HOLD the ENGAGE footswitch for the necessary amount of time (for example 1, 2, or 4 beats), and the entire phrase will re-align to match your new timing — without changing pitch!
RECORD
Press and hold the REC footswitch to initiate buffer acquisition. Recording remains active while the switch is held and terminates upon release.
Maximum phrase length = 12 seconds. Minimum length is unconstrained and can be below 100 ms.
Short-duration captures function as static spectral filters, formant matrices, resonant kernels, or glitch-state transfer sets.
Long-duration captures function as looping modulation landscapes, rhythmic convolution maps, spectral vocoders, and full-scale donor datasets.
PLAY PHRASE
Press both footswitches simultaneously (REC + ENGAGE) to output the recorded phrase directly through the main output bus, with all RED Layer modifications applied (Pitch, Stretch, Tone, Damage).
Primary purposes include:
• Auditioning captured phrase content.
• Monitoring how RED Layer parameters alter the phrase dataset.
• Using the system as a static phrase playback engine or sustained drone source.
Not designed as a conventional looper — but phrase-loop playback is supported.
PHRASE RETIME
Allows rapid temporal realignment of the recorded phrase without modifying pitch, stretch, or spectral content.
If the recorded phrase is being used as a modulation or convolution source and the user wishes to change tempo or rhythmic alignment:
Press and hold the ENGAGE footswitch for the duration corresponding to the target timing window (e.g., 1, 2, or 4 beats).
The engine performs time-normalization on the phrase, aligning it to the new temporal reference while preserving pitch and spectral structure.

↓THIS WAS A LIMITED RELEASE
The RECODER was available as a special Black Friday / End-of-Year release of 2025. No units are available for purchase.


MATH SERIES is our new playground for digital invention — a space where sound isn’t just processed, but interpreted, reshaped, deconstructed, and reborn through code. We call it Creative Signal Processing..
Yes — we’re still the PLASMA People. We’re still the MOTOR people. We’re still the team that pulled reverb out of infrared reflections on a metal spring. That mission continues – always. But now, we’re venturing into a parallel universe —and we’re approaching it the only way we know how:
Inventing new digital-native instruments that are unique, strange, expressive, and unpredictable – and the RECODER is the very first creature to walk out of that laboratory.
↑ this will sign you up to our newsletter ↑

SAMPLE-BASED EFFECT GENERATOR
The RECODER is a new kind of musical tool that lets you turn any recorded phrase into a living, breathing unique audio effect:
Record any sound, a riff, a melody, a beat, a hiss, a glitch — and use the RECODER to imbue your dry signal with various properties of the captured “spectral donor”
You can record from the main input, a separate REC input – or from the built in microphone!
You can think of it a Cross-Pollinator, an Audio Prism, a Ghostly Vocoder, a Formant Shifter, a Granular Echo Creator, or a Sound Imprint Machine…
…we have defined it a SPECTRAL MORPHING WORKSTATION, but honestly – even we don’t fully know what the RECODER is yet, because it is specifically designed to produce a unique audio effect in every player’s hands.
READY TO ROLL THE DICE?
DETERMINISTIC SPECTRAL TRANSFER & CONVOLUTION ENGINE
The RECODER is a phrase-driven signal processor that converts any recorded audio input into an adaptive, parameter-dependent transformation system.
Any captured phrase — tonal, atonal, periodic, non-periodic, harmonic or noise-based — becomes a spectral donor, supplying multidimensional data: formant structure, transient topology, temporal contour, and frequency-distribution matrices.
These datasets are then used to modulate, convolve, resynthesize, imprint, or structurally transform the incoming dry signal.
Audio can be sourced from Input A (Main signal path), Input B (Dedicated REC bus), or from the unit’s internal microphone, each routed into the spectral acquisition stage for FFT-domain capture.
It can be interpreted as a spectral transfer matrix, a convolution-driven imprint engine, a dynamic formant translator, an adaptive granular decoder, or a phrase-based modulation processor.
We classify it as a Spectral Morphing Workstation, although its behavior is intentionally non-fixed and algorithmically dependent on user-input variation.
Its operational identity changes according to the spectral complexity, temporal structure, and excitation method used by each player.
READY TO INITIATE STOCHASTIC NON-DETERMINISTIC OUTCOME GENERATION BY METAPHORICALLY “ROLLING” ONE OR MORE RECTANGULAR SOLID OBJECTS — TYPICALLY UNIFORM SIX-FACED POLYHEDRA WITH EQUAL EDGE LENGTHS, COMMONLY REFERRED TO AS DICE — WHOSE TERMINAL RESTING ORIENTATION AFTER FREEFALL AND SURFACE COLLISION DETERMINES A DISCRETE NUMERICAL RESULT USED IN PROBABILITY-BASED DECISION SYSTEMS?

At its core, the RECODER is designed for single-input recording and processing. Plug your instrument into the Main Input — guitar, synth, voice, drum machine, acoustic pickup, modular — and just roll the dice:
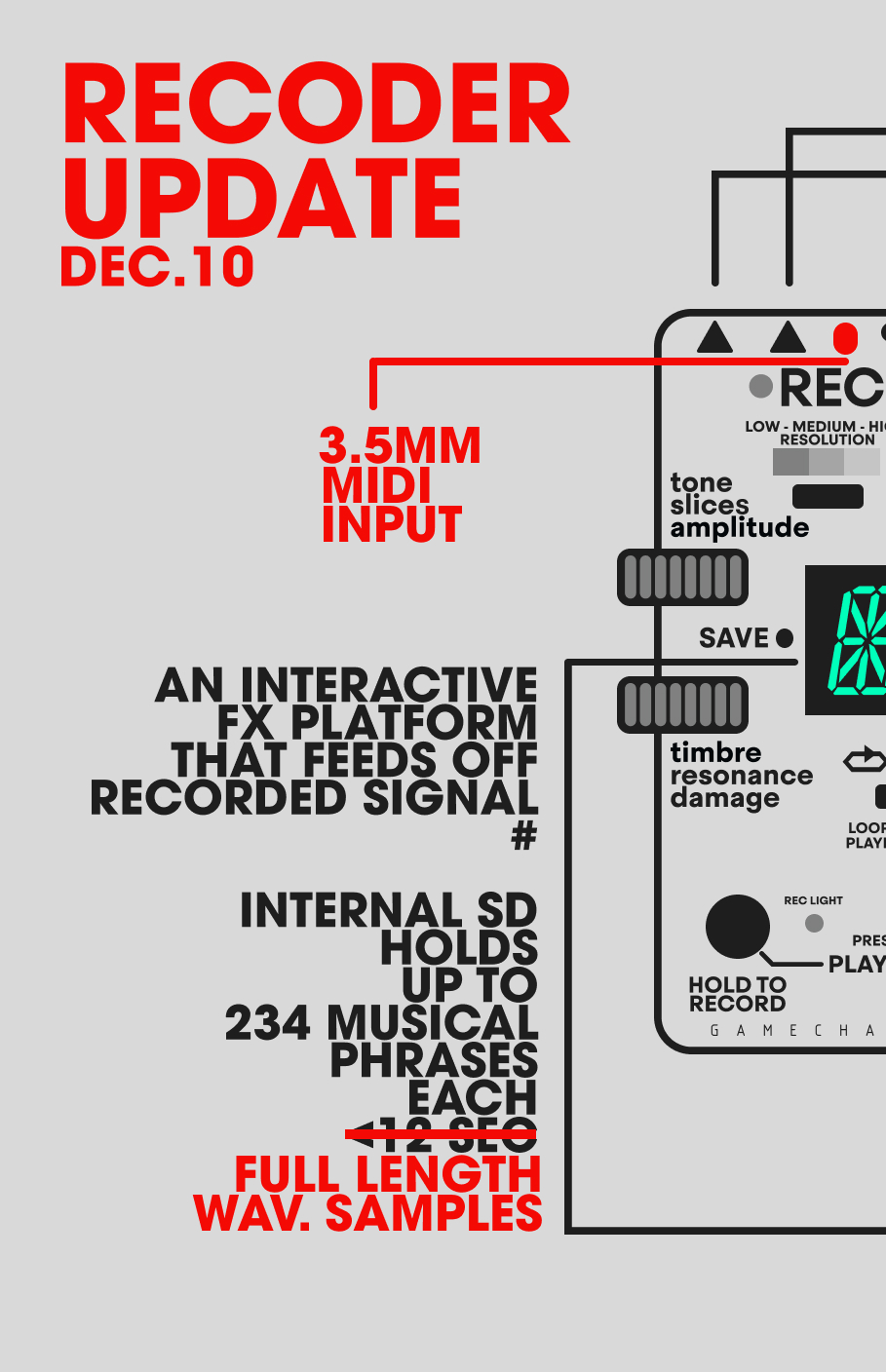
1. Record a phrase by holding down the REC footswitch – the maximum length is full length WAV samples;
2. See it being captured on the circular LED display;
3. As soon as you release the REC Footswitch – the phrase will start looping inside the memory buffer; after release;
4. Play your instrument through the phrase — and watch your live signal get interpreted, reshaped, filtered, sliced, and harmonically re-mapped – or RECODED – through that phrase…
Every phrase you capture can be saved permanently inside the pedal, stored in one of 234 memory slots –
along with all its customized parameters, layers, mangles, and mutations.
Short phrases (50–200 ms) behave like spectral filters, resonators, or timbral imprints;
Long phrases (up to full length WAV samples) become living rhythmic maps, transient machines, vowel vocoders, spectral landscapes, phantom riffs that live inside your clean sound.
At its core, the RECODER is built for single-channel phrase acquisition and deterministic processing.
Connect any excitation source to the Main Input — guitar, synth, voice, drum machine, acoustic pickup, modular — and initiate phrase capture:
1. Hold the REC footswitch to begin buffer acquisition (maximum phrase length = full length WAV sample).
2. Capture progress is visualized via the circular LED matrix (1 LED = 1 s).
3. Upon release of REC, the recorded phrase is written to volatile RAM and immediately enters loop-state.
4. Live input is streamed through that phrase as a reference dataset — where it is interpreted, filtered, time-sliced, convolved, resynthesized, and spectrally remapped using deterministic phrase-based convolution.
Each captured phrase can be permanently stored in non-volatile memory — assigned to one of 234 indexed slots — along with all mutation parameters, spectral transformations, layer states, and modulation configurations.
Micro-phrases (50–200 ms) function as spectral filters, resonant kernels, and timbral imprint matrices.
Macro-phrases (up to full length WAV samples) behave as rhythmic convolution maps, transient arrays, formant distribution engines, spectral architectures, and deterministic phrase-based excitation systems.
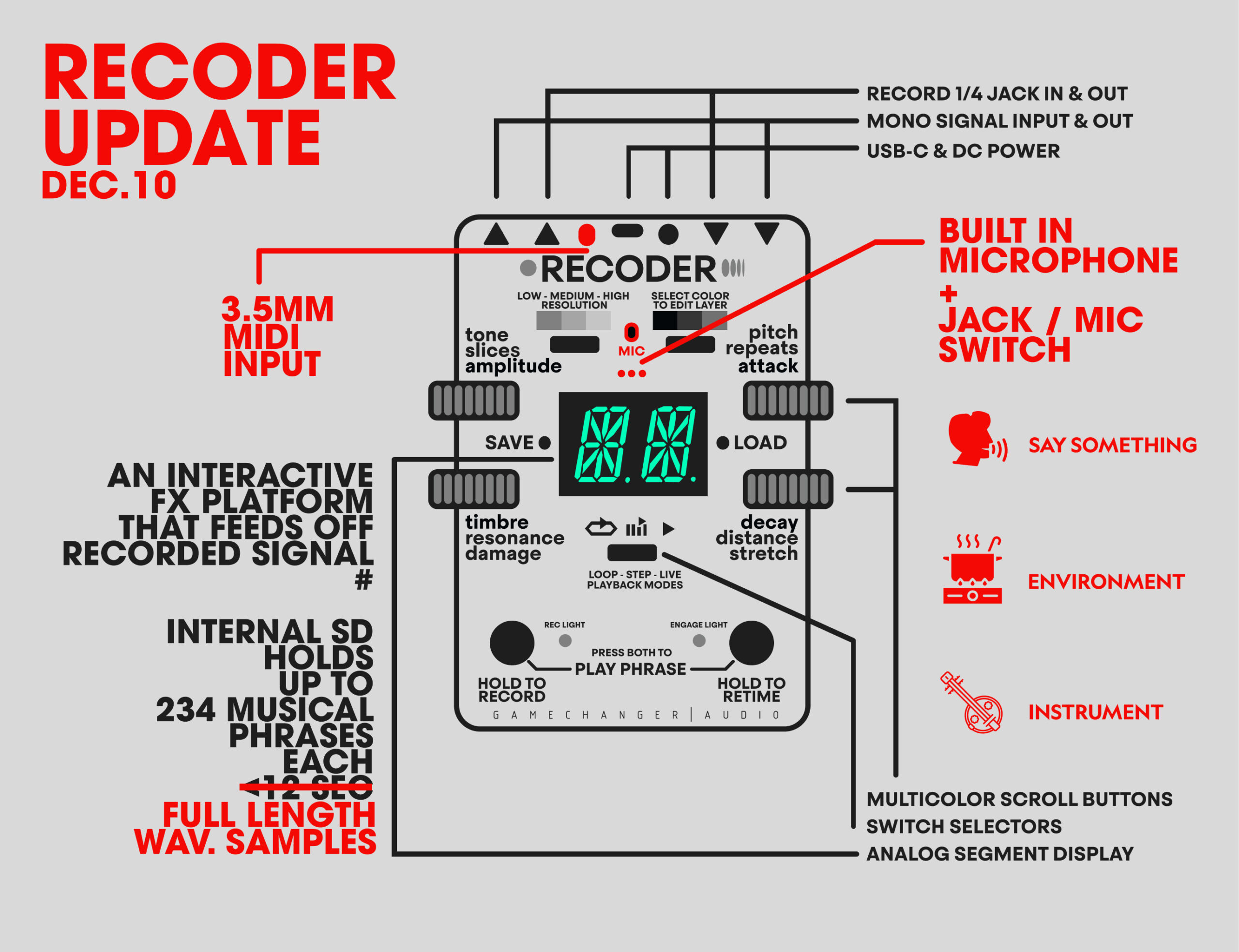
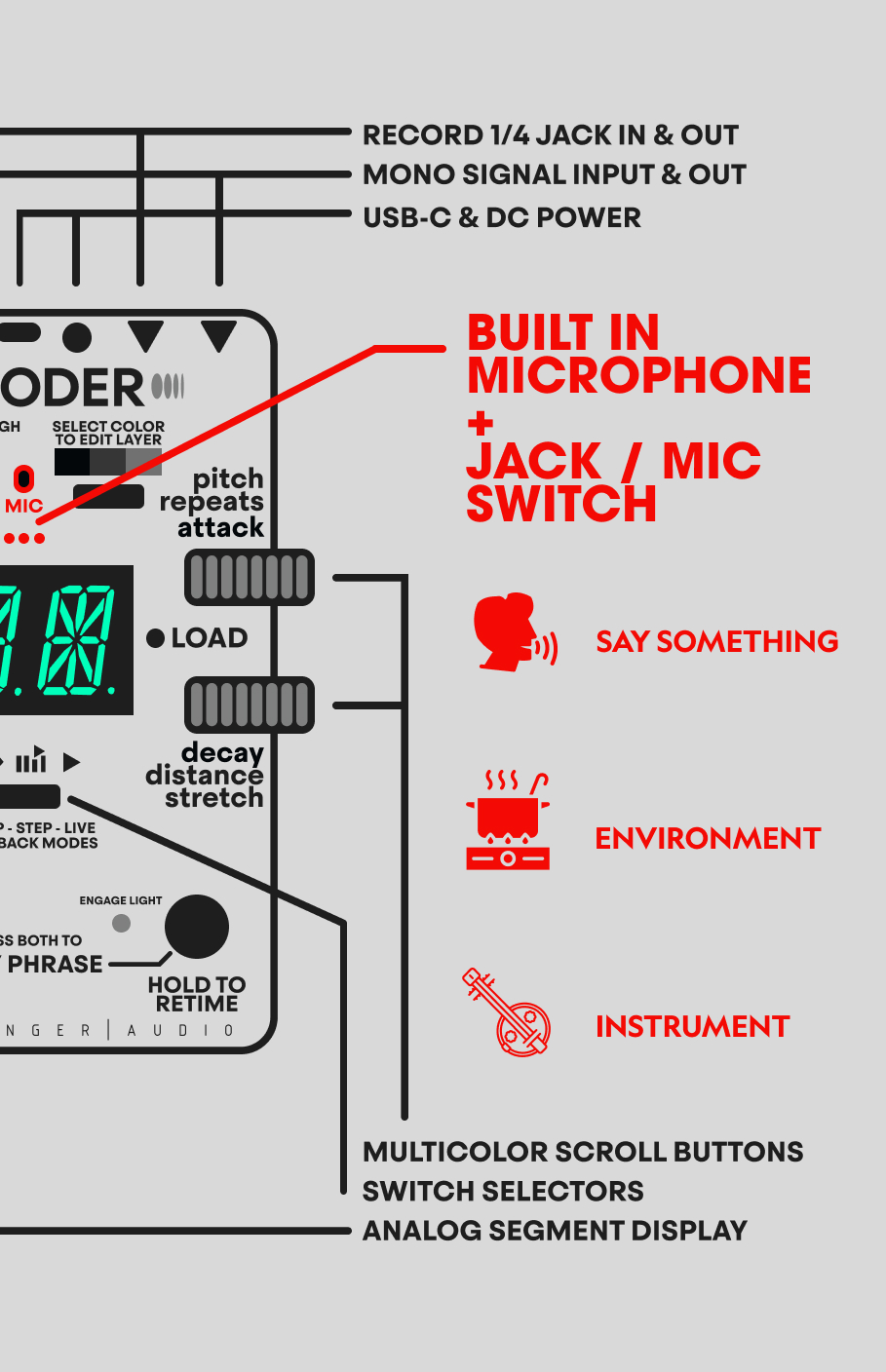
The REC Input (or the internal microphone) allows you to record external donor material from a different source in real time while still playing through your main instrument. That means you can create hybrid phrases from different sources without unplugging or stopping the flow, for example:
– Play guitar while grabbing phrases from your synth or groove-box;
– Record a vocal snippet while singing and use it to filter a drum loop, etc.;
But where the REC input truly shines, is the LIVE MODE – specifically designed to cross-pollinate instruments, pedals, synths & signals in real time.
This means that you’re no longer just playing through saved phrases — you’re feeding it new material mid-performance, constantly changing how the signals get RECODED.
The REC Input enables external donor acquisition from a secondary signal path in real time — while maintaining continuous excitation through the main input. This allows generation of hybrid phrase datasets without rerouting or interrupting signal flow. For example:
– Perform on the main input while capturing donor data from a synth or groove engine
– Capture a vocal imprint and use it as a spectral transfer matrix for a percussive source
Where the Record Input becomes structurally significant is in LIVE MODE — a dedicated real-time cross-modulation environment for continuous phrase replacement, donor injection, and inter-signal imprinting.
In this state, you are no longer processing through static, pre-saved phrase buffers —
you are actively feeding evolving donor material mid-performance, continuously redefining how the input signal is interpreted, filtered, convolved, resynthesized, and RECODED.
The White Layer is all about taking your dry signal and infusing it with the behavior, movement, and personality of the recorded phrase. There are four main controls:
AMPLITUDE – Transfer the Dynamics
Turn left → it subtracts the most active frequencies (a soft, pulsating tremolo that follows the phrase’s rhythm).
Turn right → it boosts those active bands, acting like a living multi-band booster — and if pushed far, it becomes a phrase-driven multi-band distortion.
TIMBRE – Transfer the Flavor
This control captures only the tonal DNA of the recorded phrase & superimposes it onto the input without changing dynamics.
It’s like borrowing the voice, texture, color, and grit of the phrase — and letting your playing speak through it.
Turn Left → vocoder-style imprint (grainy, glassy, responsive)
Turn Right → Additive resynthesis (cleaner, harmonic, melodic)
BANDWIDTH SWITCH – Coarse | Medium | Precision
This switch changes the WHITE LAYER’s BANDWIDTH:
how finely the amplitude & timbre engines process both signals:
LOW: Wide, chunky spectral bands; Thick, raw, lo-fi, expressive
MEDIUM: Partial spectral resolution, Balanced, musical, textured
HIGH: Full FFT spectral resolution (up to 1024 bands)
Super-detailed, surgical, spectral mapping.
Sometimes lower resolution sounds more musical.
Sometimes high resolution sounds more digital than digital.
Your call.
ATTACK & DECAY – Feel the Response Curve
These two knobs control how responsive, smooth, or sharp the transfer feels.
ATTACK: how quickly the Recoder reacts to your playing
DECAY: how long it “holds onto” the phrase’s energy before morphing to the next moment.
The White Layer applies deterministic parameter mapping between the dry input stream and the recorded phrase dataset using dynamic, spectral, and temporal transfer algorithms. It consists of four primary control domains:
AMPLITUDE — Multiband Dynamic Transfer Function
Executes dynamic convolution between the input’s amplitude envelope and the phrase’s energy-distribution coefficients.
• Turn Left → Attenuates spectral regions with highest activity in the phrase dataset, producing phrase-synchronous amplitude subtraction and rhythmic energy suppression.
• Turn Right → Increases gain in spectral regions indexed by the phrase’s transient-energy vector. At higher magnitudes, transitions into phrase-driven multiband distortion via non-linear transfer shaping.
TIMBRE — Spectral Fingerprint Transfer Algorithm
Performs convolution-based harmonic and formant embedding, applying the phrase’s spectral centroid, formant matrix, and partial-distribution topology onto the input, independent of amplitude.
• Turn Left → Low-order coefficient blending; vocoder-style transfer; coarse formant imprint; timbral color grafting; high textural density.
• Turn Right → Additive resynthesis; higher-order harmonic reconstruction; spectral smoothing; cleaner, harmonic-accurate imprinting.
BANDWIDTH SWITCH — Resolution Scaling (Coarse | Medium | Precision)
Controls FFT partition density and bin-resolution granularity for amplitude and timbre transfer:
• Low Resolution → 16–64 spectral clusters; broadband grouping; macro-imprint behavior; coarse, expressive, low-fidelity spectral emphasis.
• Medium Resolution → 128–256 partitions; partial spectral fidelity; balanced timbral accuracy and expressiveness.
• High Resolution → 512–1024 bins; full-spectrum precision; surgical mapping; analytically accurate transfer.
Lower resolutions emphasize macro-behavior and tonal character.
Higher resolutions emphasize spectral precision and analytical detail.
ATTACK & DECAY — Temporal Response Curve Shaping
Defines system responsiveness in the time domain for dynamic and spectral adaptation.
• Attack — Rise-time constant; determines how rapidly the live input aligns with the phrase-derived transfer function.
• Decay — Fall-time constant; determines persistence of the applied imprint before transitioning to subsequent transfer frames.
Together, these parameters shape responsiveness, temporal smoothing, and persistence of the spectral and dynamic imprint systems.
The Yellow Layer allows parts of the actual recorded material to start leaking into your output as an additional moving layer of sound.
SLICES – Blending in little pieces of the recorded phrase
Turn Right → adds overlapping, sympathetic spectral content from the recorded Phrase – harmonically aligned with what you are currently playing – Melodic, vowel-like, responsive.
Knob position determines the amount of signal added.
Turn Left → slices become unpredictable, dissonant, metallic, glitchy, broken, alien — based on the differences between your playing and the phrase.
RESONANCE – Real-time harmonic blooms from the recorded phrase.
Resonance analyzes the pitch and harmonic content of your recorded phrase and creates artificial boosted resonances on top of your dry signal.
Turn Left → the resonances follow what you’re currently playing, but shaped by the phrase’s tonal DNA.
Turn Right → the resonances are locked inside the phrase, regardless of what note you’re playing – creating strange harmonic overlays that sometimes agree, sometimes fight you — sometimes sound like your instrument is being haunted.
REPEATS & DISTANCE – Time-based mutation of those slices and resonances.
Once Slices and Resonances are triggered, these two knobs decide how they behave in time:
REPEATS: How many times those fragments are repeated — from one single blink to long, blooming, feedbacking tails. Invert the Knob to activate the Sound on Sound mode – thus stacking the delays.
DISTANCE: How widely spaced or tightly clustered those fragments are:
Turn Left → millisecond range where you can make granular washes that sound like a spectral freeze or a grainy reverb;
Turn Right → normal range that goes all the way up to 10 seconds – this is the ultimate playground for evolving textures.
The Yellow Layer introduces phrase-originating time-domain and frequency-domain events into the output signal path as an additional deterministic layer.
SLICES — Threshold-Based Granular Phrase Extraction
Generates phrase fragments by extracting micro time-windows when correlation between input excitation and phrase spectral data exceeds (or fails to exceed) defined band-specific thresholds.
Turn Left → Fragment triggering prioritizes low-correlation events; selection biases toward high deviation between input and phrase spectral data (non-aligned, dissonant, non-predictive behavior).
Turn Right → Fragment triggering favors high-correlation detection; phrase segments are extracted and aligned according to spectral similarity, harmonic matching, and temporal relevance.
RESONANCE — Convolution-Based Harmonic Reinforcement
Generates synthetic resonance structures by convolving the input spectrum with the harmonic and formant distribution coefficients derived from the recorded phrase.
Turn Left → Convolution coefficients are modulated in real time according to input pitch and spectral position, constrained by the phrase’s frequency-distribution matrix.
Turn Right → Convolution coefficients remain phrase-fixed, independent of input pitch; output presents static resonance mapping derived solely from phrase spectral architecture.
REPEATS & DISTANCE — Temporal Recurrence and Dispersion Control
Once Slices or Resonance events are triggered, these parameters govern recursion and temporal spacing.
REPEATS — Regulates event recurrence count and feedback persistence, from single-trigger operation to extended recursive propagation. Inverted knob mode enables cumulative sound-on-sound stacking.
DISTANCE — Sets temporal spacing between repeated events.
Turn Left → Sub-100 ms range for granular clustering and continuous spectral-density accumulation.
Turn Right → Extended spacing (up to 10 seconds) for macro-scale time dispersion and evolving transfer structures.
Since the RECODER is a pedal that sounds completely differently depending on what you feed into it – we’ve created a whole layer of controls dedicated to altering the recorded phrase itself:
TONE – Tilt the Energy:
This is a dramatically strong tilt-EQ engine that autonomously picks its center “tilt” point based on analysis of the recorded phrase or sample — so yes, even the TONE knob is alive & completely dependent on what you record:
DAMAGE – Obliterate the sample:
and start a chain reaction that changes everything you had dialled in…
Turn Left → bit reduction, digital degradation, crunchy broken beauty.
Turn Right → full-on wavefolding – shredding the phrase into aggressive, harmonic-dense chaos.
PITCH – eight whole octaves:
Turn the Pitch knob to drop or lift the entire recorded phrase by up to 4 octaves – but here’s the twist: the timing doesn’t change.
You get time-corrected pitch shifting – meaning you can record a tiny pinch harmonic and drop it down all the way to a rumbling thunder — without stretching or slowing it down.
STRETCH – Bend time without breaking the seams:
This is a time-stretching engine that is completely decoupled from pitch — take a 50-millisecond sample and stretch it into a grainy, long texture and enjoy the trip. Or, alternatively, you can record the intro to thunderstruck and speed it up so it sounds like a swarm of bumblebees.
RED Layer modifies the recorded phrase dataset itself, altering its spectral, temporal, and harmonic properties before any further transfer or convolution.
TONE — Autonomous Spectral Tilt Engine
Applies adaptive tilt equalization by shifting energy distribution around a dynamically computed spectral pivot point.
The pivot frequency is not fixed — it is derived from statistical analysis of the phrase’s spectral centroid, energy-weighted formant distribution, and dominant harmonic clusters.
All tilt behavior is phrase-dependent; no static EQ curves are used.
DAMAGE — Sample Degradation and Harmonic Mutation
Applies progressively non-linear transformation to the recorded phrase, altering its spectral and structural integrity.
Turn Left → Initiates bit-depth reduction, quantization error, and digital aliasing artifacts. Harmonic and temporal resolution are reduced according to statistical truncation parameters.
Turn Right → Engages wavefolding and harmonic multiplication, introducing non-linear distortion, spectral inversion, and high-density harmonic proliferation.
Modifying DAMAGE propagates through all dependent transfer engines (Amplitude, Timbre, Resonance, Slices, Pitch, Stretch).
PITCH — Time-Invariant Transposition Engine
Transposes the entire recorded phrase across an eight-octave span (±4 octaves) while preserving original temporal structure.
Time-independent pitch shifting maintains phrase duration, temporal segmentation, transient position, and rhythmic architecture without stretching or compression.
Applies phase-coherent resynthesis to preserve structural continuity.
STRETCH — Pitch-Decoupled Time Expansion and Compression
Performs time scaling on the recorded phrase while maintaining original pitch, spectral distribution, and formant structure.
Expand short segments into extended granular structures, generating long-form spectral density without altering pitch.
Compress long segments into accelerated micro-structures without pitch shift, maintaining spectral identity.
Time scaling is executed via pitch-decoupled granular resynthesis with phase-locking for coherence.


LOOP Mode – Circular Playback
This is the default mode – the one we’ve focused on in all previous sections, and the mode that inspired the RECODER idea initially!
In LOOP mode, the recorded phrase is constantly spinning inside the engine — like a circular buffer. The playhead continuously cycles through the phrase, over and over again.
STEP Mode – Dynamic Playhead
RECODER analyzes the recorded phrase and splits it into segments based on transients and pitch changes — like tiny “phrase markers” or event points.
The playhead only advances when you trigger it with your playing.
Each time you strike a note or hit a transient — the engine jumps to the next slice, segment, or pitch zone in the recorded phrase.
This is the ideal mode for breaking out of a set rhythmical pattern, and for introducing a sense of responsivity – where all changes in the RECODER’s spectrum come directly from you!
* Advance Sensitivity & Threshold can be adjusted in Global Settings.
LIVE Mode – Real-time side-CODING
Instead of relying on saved phrases as the signal source — the RECODER uses your live input as the spectral donor – essentially becoming a real-time spectral resynthesis and cross-morphing machine.
You can still record a phrase and RECODE through it – but as soon as you unlatch the REC Footswitch – you can go right back to the LIVE input as the modulation source.
LOOP Mode — Continuous Buffer Cycling
Default operational mode.
The recorded phrase is stored as a circular buffer. A fixed-position playhead continuously cycles through the entire phrase in a closed loop, maintaining uninterrupted time progression.
All spectral, temporal, and harmonic transfer computations are driven by the current playhead position within the phrase.
STEP Mode — Event-Driven Playhead Advancement
The recorded phrase is segmented into discrete units based on detected transient peaks, spectral discontinuities, and pitch-zone boundaries. These become internal event markers.
The playhead does not advance continuously — it advances only when triggered by the input signal.
When a new transient or note onset is detected at the input, the playhead jumps to the next indexed event marker (segment, slice, or pitch zone).
This yields phrase navigation that is directly mapped to user excitation.
Sensitivity, detection threshold, and segmentation density are adjustable in Global Settings.
LIVE Mode — Real-Time Side-Coding and Cross-Morph Resynthesis
In this mode, the spectral donor is no longer strictly the stored phrase. Instead, the engine dynamically acquires spectral frames from the live input and uses them for real-time convolution, harmonic transfer, and parameter resynthesis.
A stored phrase may still be used as a reference, but once the REC footswitch is unlatched, the system begins replacing donor frames continuously with incoming spectral data.
This enables live, continuously updated cross-morph processing — effectively converting the system into a real-time spectral resynthesis engine.
SENSITIVITY & IN LEVEL — how reactive the Recoder is to your playing, how easily slices trigger, how ADVANCE mode steps through the phrase, how soft or aggressive the transient detection is.
SLOT STATE SETUP — defines how presets behave: whether Slots store just settings or also the recorded phrase, whether mutations like Pitch and Stretch are saved, whether the pedal always boots into the last-used Slot, etc.
MIDI — choose the MIDI channel, assign CC or Program Change, and decide which parameters can be controlled externally (Pitch, Stretch, Damage, Record, Load, Play Phrase, etc.). No forced templates — you assign what matters.
FOOTSWITCH BEHAVIOUR — define whether Play Phrase is momentary or latch, whether Retime is quantized or free, whether Record overwrites or keeps the last sample.
SYSTEM SETTINGS — LED display mode, USB behavior, boot Slot, Live mode on/off, and other small but practical things.
SENSITIVITY & IN LEVEL — defines input excitation response thresholds, governing transient-detection tolerance, slice-trigger activation probability, and ADVANCE-mode step progression behavior. Controls overall reactivity to amplitude, spectral change, and temporal onset parameters.
SLOT STATE SETUP — determines memory state behavior: whether Slots store only parameter configurations or also the recorded phrase dataset; whether transform states such as Pitch, Stretch, and Damage are persisted; defines boot-state behavior (e.g., auto-load last-used Slot vs. default Slot initialization).
MIDI — specifies MIDI channel assignment, CC and Program Change mapping, and external control routing. Enables selection of controllable parameters (Pitch, Stretch, Damage, Record, Load Phrase, Play Phrase, etc.). No fixed mapping schema; user-defined assignment only.
FOOTSWITCH BEHAVIOUR — configures control logic for footswitch operations: defines whether Play Phrase is latch or momentary; whether Phrase Retime is quantized or free; whether Record overwrites existing data or retains previous phrase buffer.
SYSTEM SETTINGS — defines global system parameters: LED display mode, USB I/O behavior, default boot Slot, Live Mode enable/disable, and other non-audio operational configurations.
RECORD
Press and hold the REC footswitch to start recording. Recording starts as long as the switch is held down and stops when you release it.
Maximum phrase recording time is 12 seconds, but the recorded phrase can be as short as you like — even less than a hundred milliseconds.
Short captures behave like static filters, timbre captures, resonators, glitch artifacts. Long captures become looping “landscapes,” rhythmic machines, spectral vocoders, ghost riffs, etc.
PLAY PHRASE
Press both footswitches at the same time | REC + ENGAGE | and the RECODER will play the phrase directly through the output — with all of the RED parameters applied:
pitch, stretch, tone, damage.
This is extremely useful for:
– Checking what you actually recorded;
– Hearing how the Red Layer settings changed the phrase;
– Using the RECODER like a tiny sample playback or drone/phrase looper!
It’s not a looper pedal —
but yes, you can loop.
PHRASE RETIME
This is a clever shortcut for quickly re-timing or “stretch-aligning” the recorded phrase to match what you are playing now without changing pitch, stretch values, or any of the spectral content.
Let’s say you recorded a rhythmic pattern and you’re using it as a modulation source — but now you want to switch to a different tempo:
PRESS & HOLD the ENGAGE footswitch for the necessary amount of time (for example 1, 2, or 4 beats), and the entire phrase will re-align to match your new timing — without changing pitch!
RECORD
Press and hold the REC footswitch to initiate buffer acquisition. Recording remains active while the switch is held and terminates upon release.
Maximum phrase length = 12 seconds. Minimum length is unconstrained and can be below 100 ms.
Short-duration captures function as static spectral filters, formant matrices, resonant kernels, or glitch-state transfer sets.
Long-duration captures function as looping modulation landscapes, rhythmic convolution maps, spectral vocoders, and full-scale donor datasets.
PLAY PHRASE
Press both footswitches simultaneously (REC + ENGAGE) to output the recorded phrase directly through the main output bus, with all RED Layer modifications applied (Pitch, Stretch, Tone, Damage).
Primary purposes include:
• Auditioning captured phrase content.
• Monitoring how RED Layer parameters alter the phrase dataset.
• Using the system as a static phrase playback engine or sustained drone source.
Not designed as a conventional looper — but phrase-loop playback is supported.
PHRASE RETIME
Allows rapid temporal realignment of the recorded phrase without modifying pitch, stretch, or spectral content.
If the recorded phrase is being used as a modulation or convolution source and the user wishes to change tempo or rhythmic alignment:
Press and hold the ENGAGE footswitch for the duration corresponding to the target timing window (e.g., 1, 2, or 4 beats).
The engine performs time-normalization on the phrase, aligning it to the new temporal reference while preserving pitch and spectral structure.
THIS WAS A LIMITED RELEASE
The RECODER was available as a special Black Friday / End-of-Year release in 2025. No units are currently available for purchase.
MATH SERIES is our new playground for digital invention — a space where sound isn’t just processed, but interpreted, reshaped, deconstructed, and reborn through code. We call it Creative Signal Processing..
Yes — we’re still the PLASMA People. We’re still the MOTOR people. We’re still the team that pulled reverb out of infrared reflections on a metal spring. That mission continues – always. But now, we’re venturing into a parallel universe —and we’re approaching it the only way we know how:
Inventing new digital-native instruments that are unique, strange, expressive, and unpredictable – and the RECODER is the very first creature to walk out of that laboratory.
THIS WILL SUBSCRIBE YOU TO OUR SUPER HOT NEWSLETTER ^^^
THIS WILL SUBSCRIBE YOU TO OUR SUPER HOT NEWSLETTER ^^^